CPM-Live 第二期训练启动
上次还是初夏,我们发送第一封直播邀请函,埋下希望的种子,而今转眼就到了深秋—— 收获的季节 。
在这短短数月,OpenBMB 与广大关注者见证了彼此的耕耘和汗水。OpenBMB 团队耗时 68 天、花费 40 余万人民币完成了百亿大模型 CPM-Ant 的训练,社区的同学也积极参与,为 CPM-Ant 送出了 400 多个点赞,以及 100 余条新版本功能倡议。终于,我们一同收获了一期训练的累累硕果,也迎来第二期直播训练 CPM-Bee 的启动。
CPM-Bee 三大新特性
作为首个直播训练中文大模型,CPM-Ant 具有计算高效、性能优异、部署经济、使用便捷、开放民主五大卓越特性, 在大模型训练、微调、压缩、推理、应用等环节均提供了一份实践参考方案。
从 Ant 到 Bee 的形象喻指,也体现出我们的预期与展望:通过持续学习,模型将会不断变大变强。
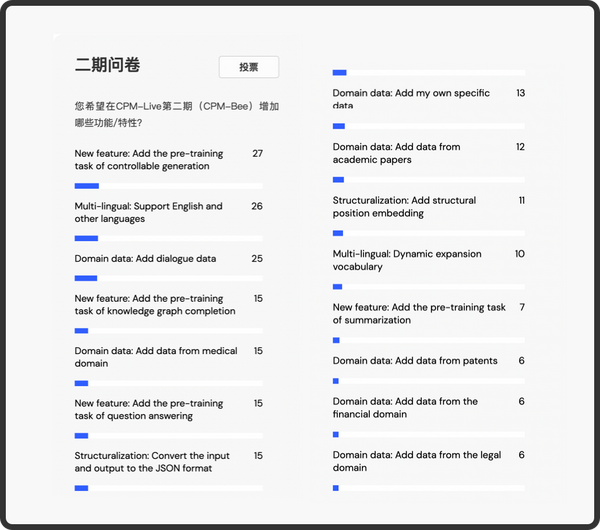
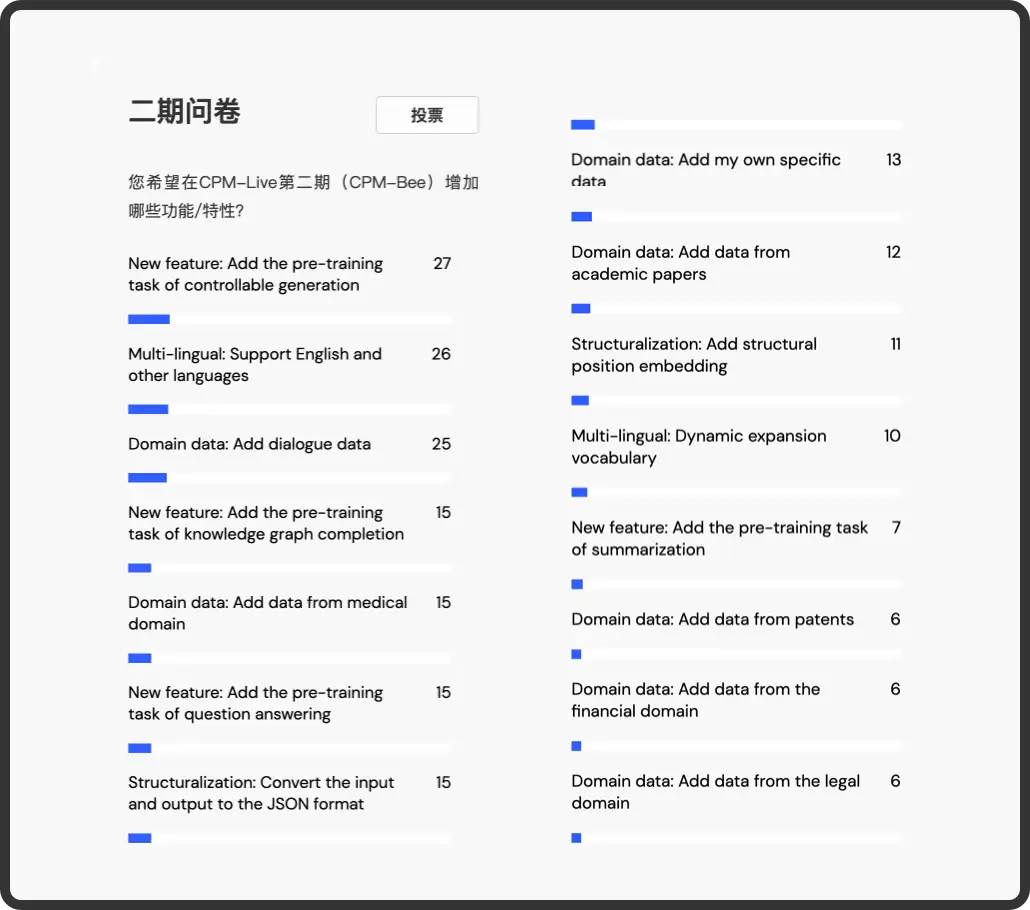
在充分考虑 OpenBMB 社区意见和团队的精心设计下,CPM-Bee 的训练中将新增 任务模式增强、多语言融合、复杂结构处理等 新特性 。具体来说,CPM-Bee 的新特性如下:
01 任务模式增强
在 CPM-Bee 中,我们会在预训练过程中引入各类常见任务模式的数据增强,包括分类、生成、问答、对话、摘要、扩写、翻译,支持 CPM-Bee 在各类文本处理任务上开箱即用,提升结合少量样本的高效参数微调的性能。
02 多语言融合
在 CPM-Ant 中,我们着重构建以中文为核心的大模型。在 CPM-Bee 中,我们将逐渐加入英文以及其他语种的数据(包括各语言独立数据及跨语言平行数据),最终形成以中文为核心,多语种兼顾的大规模预训练语言模型。
03 复杂结构处理
已有的预训练语言模型主要立足于利用非结构化文本进行训练,因而对于半结构化及结构化数据的处理能力较弱。在 CPM-Bee 中,我们会加入各类半结构化及结构化数据的处理功能,以更好地支持网页、代码等结构化复杂文本的处理能力。下方所示为结构化训练数据样例。
{ "document": "今天天气是真的<mask_0>,我们去了<mask_1>,玩得非常<mask_2>。", "<ans>": { "<mask_0>": "好", "<mask_1>": "颐和园", "<mask_2>": "开心" }
}CPM-Bee 实时训练过程
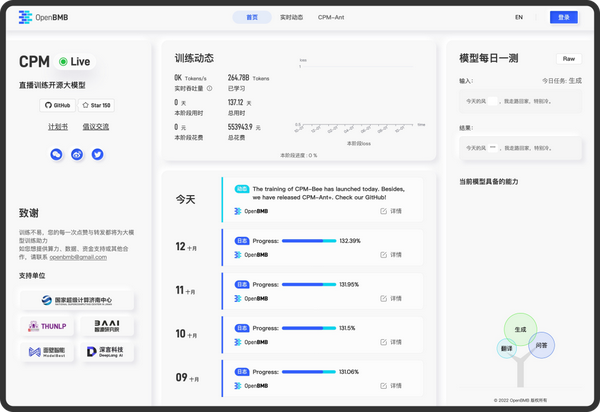
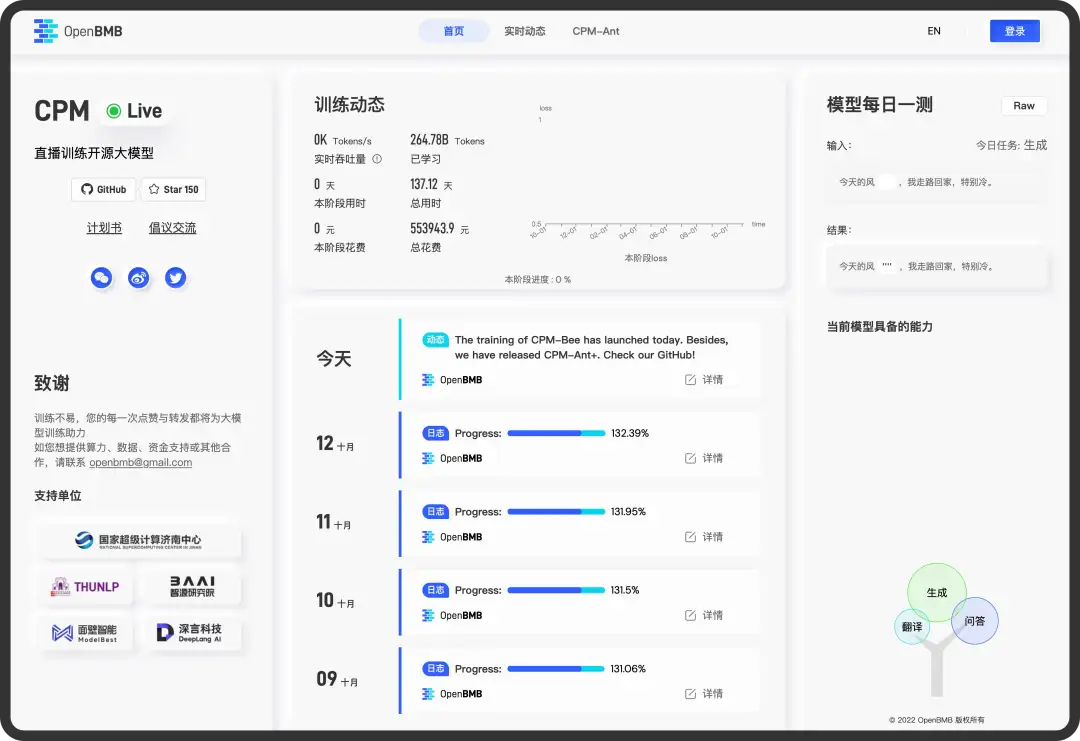
为支持 CPM-Bee 的实时展示,我们更新了网站页面。训练启动后,我们将延续第一期的网页直播形式,官网以图表、数值等直观形式,实时展示 训练过程中 GPU数、吞吐量、损失值等动态数据,方便大家随时前来“围观”。每天傍晚,我们将上传前一天的“训练日志”,各位朋友不妨多来“批改作业”。我们还额外增加了模型能力展示页面——模型每日一测 :每天针对不同 case 更新模型结果,更加直观地展示模型不断学习、不断进步的过程。在下图中可以看出,页面右上初始模型的生成结果并不佳,但随着时间的推移,我们相信,这个众目注视下的“养成系”模型会越来越强大。
➤ 传送门|官网链接 https://live.openbmb.org
欢迎前来我们 CPM-Live 项目的 GitHub,期待您使用代码、发起或参与讨论!您的试用和意见,甚至批评,都是我们最珍视的行动和声音,都将助力国产大模型从中国的一隅走向世界的大舞台!
蚁行千里人以为一寸,路漫漫其修远兮。我们已经见证了 Ant 的稳健爬行,未来我们将一起推动大模型 CPM-Bee 的起飞。
与君同行,与有荣焉!
OpenBMB 团队敬上
2022年10月13日
➤ 传送门 GitHub 链接
https://github.com/OpenBMB/CPM-Live
➤ 传送门 CPM-Bee 计划书
OpenBMB 小编碎碎念
1.如果您想为大模型直播训练加油打 call,关注本文公众号,回复 “加油群” ,添加小助手即可等待加入 CPM-Live训练加油群;
2.如果您想和更多热爱大模型的同仁交流 ,关注本文公众号,回复 “大模型” ,添加小助手即可等待加入 学习群;
3.如果您想系统学习大模型,欢迎关注我们的 B站账号 “OpenBMB” ,其中已更新全部 课程视频和配套资源;
4.如果您或您的组织有意愿提供算力、数据与资金等支持,欢迎联系邮箱 openbmb@gmail.com。

京公网安备 11010802039419号