背景介绍
2018年,预训练语言模型技术横空出世并引发了人工智能领域的性能革命。研究表明,增大参数量与数据规模是进一步提升语言模型性能的有效手段,对十亿、百亿乃至千亿级大模型的探索成为业界的热门话题。这引发了国内外研究机构与互联网企业的激烈竞争,将模型规模与性能不断推向新的高度。除 Google、OpenAI 等国外知名机构外,近年来国内相关研究机构与公司也异军突起,形成了大模型的研究与应用热潮,人工智能由此进入“大模型时代”。
然而在“大模型时代”,模型巨大的参数规模和算力需求,带来了很大的训练和微调难题:
▶ 算力成本高
模型巨大的参数量无法在单张显卡中完成存储与计算。OpenAI 训练 GPT-3 (约1750亿参数)使用了上千张 GPU,Google 训练 PaLM (约5000亿参数)使用了六千片 TPU,带来了高昂的训练成本,配置规模庞大的计算集群也十分困难。
▶ 编程难度大
为了利用分布式算力加速大模型的训练和微调,程序员需要编写复杂的分布式程序来驱动大模型。现有的框架(如DeepSpeed)已经能够较好地支持模型的分布式训练,但依然需要用户进行较为复杂的编程与配置。
▶ 计算速度低
在分布式训练框架中,不同计算节点之间需要频繁地进行通信,此时通信带宽往往成为模型的训练瓶颈,若不能合理设计通信策略并进行有效且正确的代码实现,训练模型所需的时间将被大大延长,不能充分发挥计算设备的潜力。
针对上述难题,我们推出了大模型高效训练工具包BMTrain与模型仓库ModelCenter。
BMTrain & ModelCenter
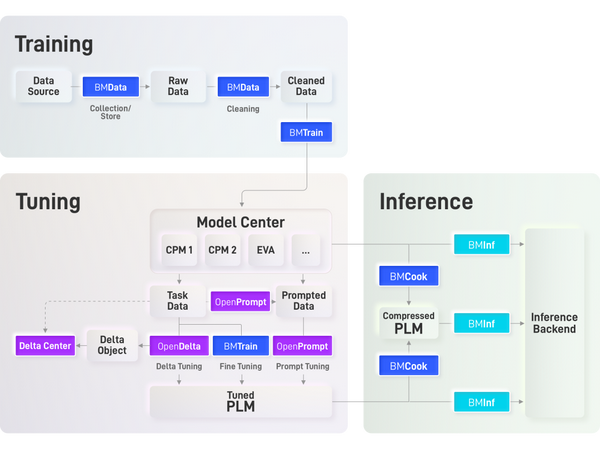
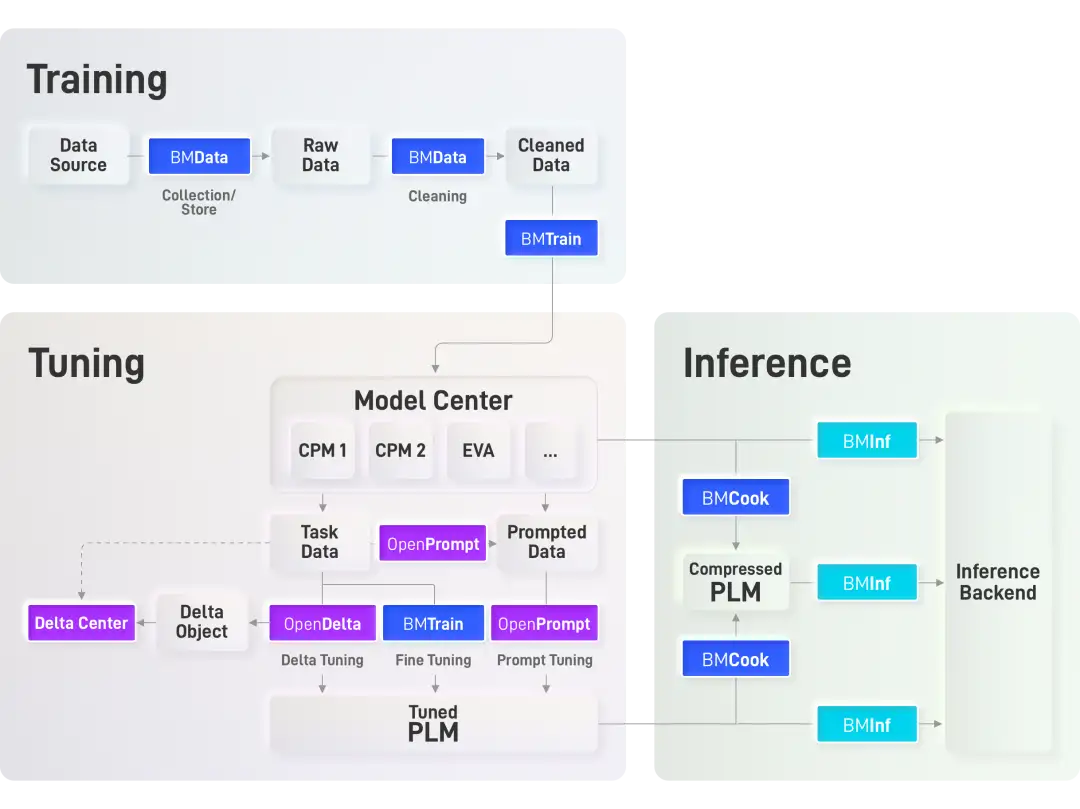
在 OpenBMB 全流程加速工具框架中,致力于解决大模型训练难题的 BMTrain 是极为重要的一环。在设计中,我们追求以下特点:
▶ 高效率
作为大模型训练的 “发动机”,BMTrain 能够在任意数量的 GPU 上进行高效的大模型预训练与微调,最优化分布式框架的通信开销,在超大规模模型训练场景下与 DeepSpeed 等框架相比可以节省 90% 的算力成本。
▶ 低资源
不同于OpenAI、Google 等机构的算力条件,为了让更多实验室和企业也能够训练大模型,我们致力于在保持高效计算前提下最小化大模型的算力需求,实现单张消费级显卡全参数微调 BERT-Large,8 台 A100 小集群训练 GPT-3,进一步降低大模型的算力门槛。
▶ 可扩展
在编程难度方面,我们致力做最简洁最有效的封装,仅使用少量的代码替换,即可达到与原生 PyTorch 一致的编程体验,一键安装工具包降低配置难度,让大模型真正飞入千家万户。


与此同时,我们还基于 BMTrain 实现了一系列大规模预训练语言模型,集成于ModelCenter 仓库。BMTrain 与 ModelCenter 共同组成了高效分布式预训练框架,适用于任意的 Transformer 结构,可以在较少数量的 GPU 上训练,且高度兼容 PyTorch、Transformers 库,学习成本极低。目前我们已经支持了常用的英文模型如 BERT、GPT、T5、RoBERTa 以及中文模型如 CPM-1、CPM-2 等。
简单易用
BMTrain 基于简单易用的设计原则,致力做最简洁最有效的封装,仅使用少量的代码替换,即可达到与原生 PyTorch 一致的编程体验,快速实现大模型的训练加速。我们还实现了模型仓库 ModelCenter,方便使用者快速使用主流架构大模型。
无缝衔接
贴合PyTorch使用习惯,上手门槛更低,仅需简单替换即可完成训练提速:
bmtrain.DistributedParameter替换torch.nn.Parameter
bmtrain.DistributedModule替换torch.nn.Module
bmtrain.CheckpointBlock替换torch.nn.ModuleList中的模块
下面将提供一个简单的对比图来直观展示BMTrain的便捷易用(左边是原始代码,右边是替换后的代码)。


一键转换
对于PyTorch实现的原始模型,直接使用BMTrain提供的BMTrainModelWrapper自动包装模型,实现分布式加速。
# Automatically wrap a model in a BMTrain model bmt_model = BMTrainModelWrapper(model) # model: torch.nn.module模型仓库
我们基于BMTrain构建了模型仓库ModelCenter,可以直接加载进行使用。ModelCenter的使用方式与Transformers类似,且兼容Transformers中各类数据处理接口。


效果拔群
BMTrain在大模型训练上效果出色,在不同规模的算力条件下均有较好的性能表现。
消费级算力(单卡2080Ti)
在消费级显卡2080Ti上,BMTrain可以实现BERT-Large的微调(3亿参数,样本长度 512)。
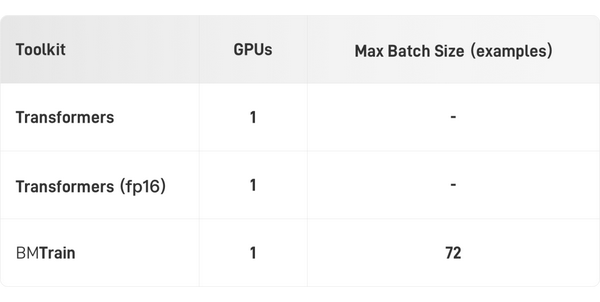
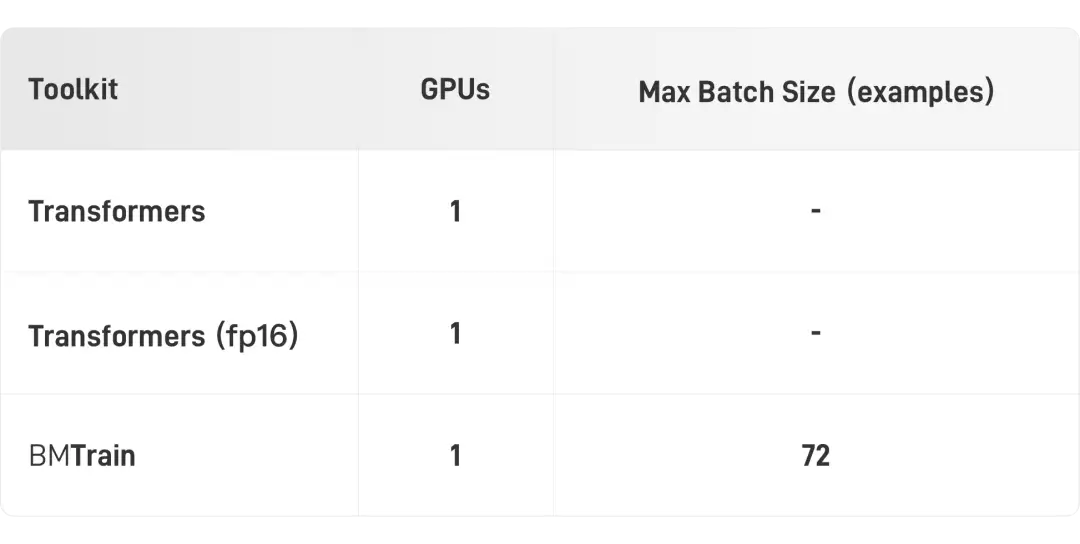
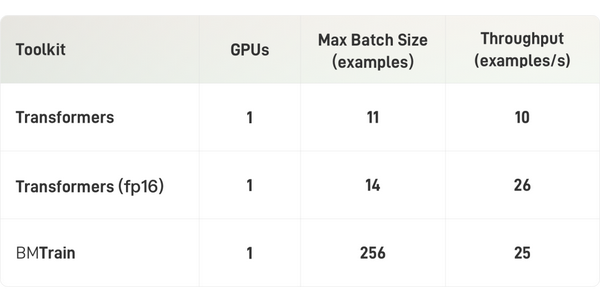
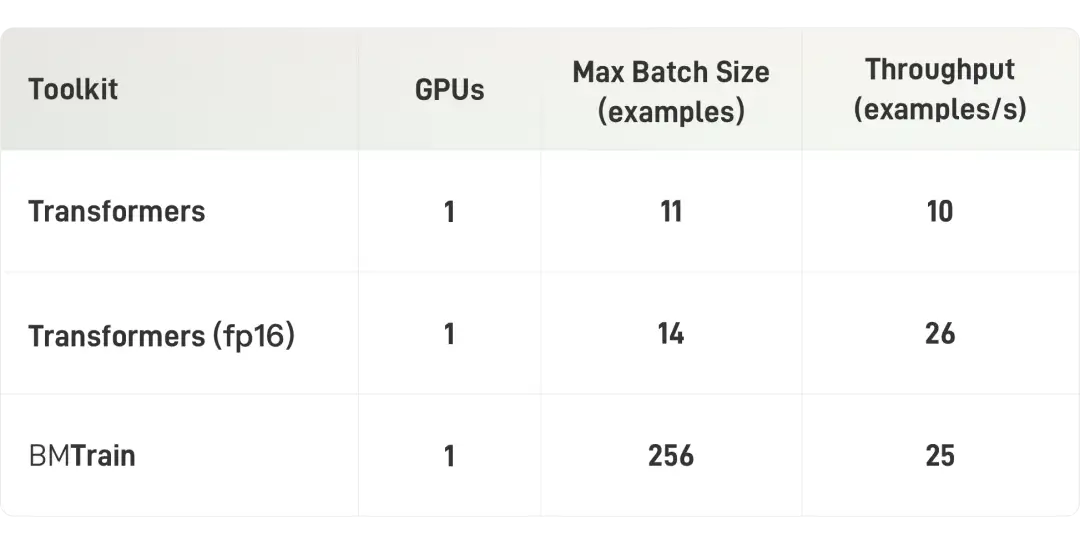
入门级算力(单卡V100)
在入门级算力条件下(显卡为V100 32GB),BMTrain可以实现BERT-Large的高效训练(3亿参数,样本长度 512)。
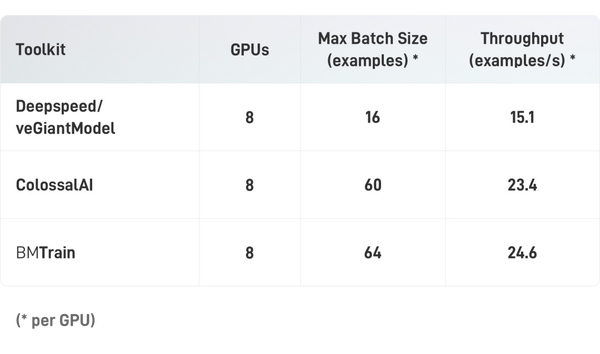
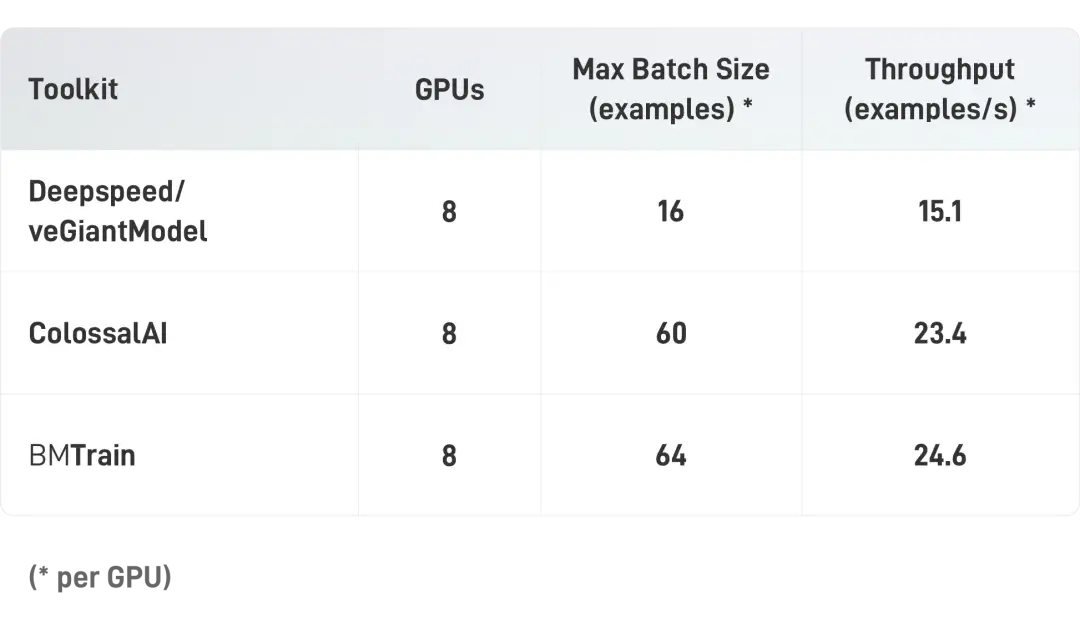
中等算力(单机8卡A100)
在中等规模算力条件下(显卡为A100 40GB,NVLink),BMTrain可以训练大规模的 GPT-13B (130亿参数,样本长度 512)。
高级算力(多机8卡A100)
在较高规模算力条件下(显卡为A100 40GB,NVLink,400Gbps IB),BMTrain可以训练超大规模的 GPT-3(1750亿参数)。
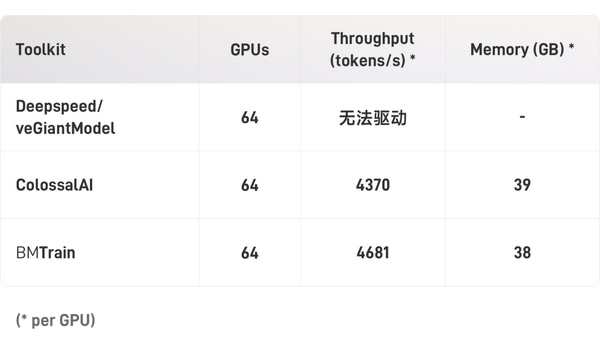
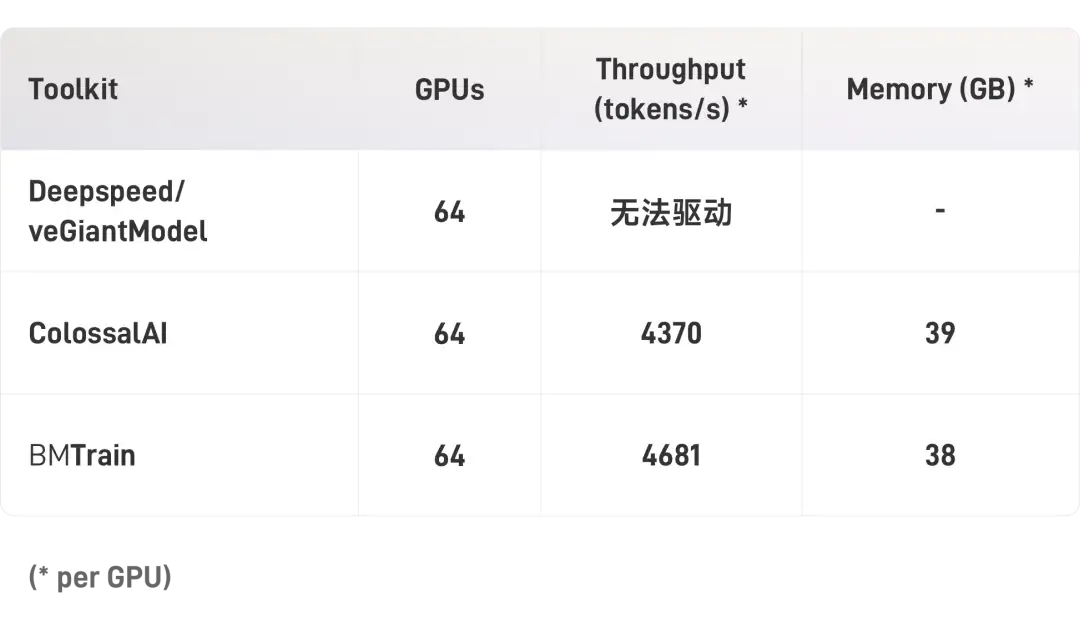
使用BMTrain或者ColossalAI,64卡A100跑完GPT-3的300B token大概需要2年,服务器与显卡租金大约900万左右。根据我们的实验估算,使用128张A100时,单卡吞吐量可以提升2.5倍以上,6个月可以跑完GPT-3,服务器租金大约500万左右。虽然训练出GPT-3的成本依然高昂,但与GPT-3的1200万美元相比,成本仍然节约了90%以上。
上手教程
BMTrain 和 ModelCenter 提供了丰富的文档,方便使用者快速上手,便捷地体验大模型的魅力。
STEP 01 · 快速安装
▶ BMTrain安装
· 可以通过pip直接安装(推荐)
$ pip install bmtrain· 也可以选择从GitHub进行源码安装
$ git clone https://github.com/OpenBMB/BMTrain.git
$ cd BMTrain
$ python3 setup.py install
▶ ModelCenter安装
· 可以通过pip直接安装(推荐)
$ pip install model-center· 也可以选择从GitHub进行源码安装
$ git clone https://github.com/OpenBMB/ModelCenter.git
$ cd ModelCenter
$ pip install -r requirements.txt
$ python3 setup.py installSTEP 02 · 启动BMTrain
首先,你需要在代码开头初始化 BMTrain。正如在使用 PyTorch 的分布式训练模块需要在代码开头使用init_process_group一样,使用 BMTrain 需要在代码开头使用init_distributed。
import bmtrain as bmt
bmt.init_distributed()注意:
使用 BMTrain 时请不要使用 PyTorch 自带的distributed模块
包括torch.distributed.init_process_group以及相关通信函数
STEP 03 · 性能优化
▶ ZeRO-3优化
使用ZeRO-3优化只需要对模型代码进行简单替换:
· torch.nn.Module替换为 bmtrain.DistributedModule
· torch.nn.Parameter 替换为 bmtrain.DistributedParameter
▶ Checkpointing优化
· 在模块上套用 bmtrain.CheckpointBlock 即可
▶ 通信优化
为了进一步缩短通信额外开销,将通信与运算时间重叠,可以使用 TransformerBlockList 来进一步优化。在使用时需要对代码进行简单替换:
· torch.nn.ModuleList 替换为 bmtrain.TransformerBlockList
· for module in self.module_list: x= module(x, ...)替换为 x = self.module_list(x, ...)
STEP 04 ·运行分布式训练代码
BMTrain 使用 PyTorch 原生分布式训练启动器,你可以根据 PyTorch 版本选择下列命令中的一个。
· torch.distributed.launch
$ python3 -m torch.distributed.launch --master_addr ${MASTER_ADDR} --master_port ${MASTER_PORT} --nproc_per_node ${GPU_PER_NODE} --nnodes ${NNODES} --node_rank ${NODE_RANK} train.py ${ARGS}· torchrun
$ torchrun --nnodes=${NNODES} --nproc_per_node=${GPU_PER_NODE} --rdzv_id=1 --rdzv_backend=c10d --rdzv_endpoint=${MASTER_ADDR}:${MASTER_PORT} train.py ${ARGS}其中:
${MASTER_ADDR} 为主节点的 IP 地址,只有一个节点可以写localhost或 127.0.0.1
${MASTER_PORT} 为主节点的端口
${NNODES} 为节点数量(一般为机器数量)
${GPU_PER_NODE} 为每个节点的 GPU 数量
${NODE_RANK} 为本节点的 RANK
${ARGS} 为代码输入的其他参数
STEP 05 · 使用ModelCenter
本节将首先以如何在一个分类数据集上微调 BERT 模型为例,介绍如何使用ModelCenter的现有模型。其次将简单介绍如何使用 ModelCenter 实现一个新的模型。
▶ 01 准备模型
接下来,你可以从 model_center 中获取预训练好的 BERT 模型,例如 bert-base-uncased。由于我们是在一个分类任务上微调 BERT 模型,所以需要在最后一层后添加一个全连接层。
import torch
from model_center.model import Bert, BertConfig
from model_center.layer import Linear class BertModel(torch.nn.Module): def __init__(self, config): super().__init__() self.bert = Bert.from_pretrained("bert-base-uncased") self.dense = Linear(config.dim_model, 2) bmt.init_parameters(self.dense) def forward(self, input_ids, attention_mask): pooler_output = self.bert(input_ids=input_ids, attention_mask=attention_mask).pooler_output logits = self.dense(pooler_output) return logits config = BertConfig.from_pretrained("bert-base-uncased")
model = BertModel(config)如果只需要 config 来构建模型,而不需要现成的预训练参数,可以参考下面的方法:
config = BertConfig.from_json_file("your/path/to/config.json")
model = Bert(config)
bmt.init_parameters(model)
# bmt.load(model, "your/path/to/pytorch_model.pt")
▶ 02 准备数据集
下一步是准备数据集,用于训练和验证模型。这里,我们使用 SuperGLUE benchmark 中的 BoolQ 数据集。你需要下载该数据集,并将解压后的文件夹放在 your_path_to_dataset 路径下。
from model_center.dataset.bertdataset import DATASET
from model_center.dataset import DistributedDataLoader
from model_center.tokenizer import BertTokenizer tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
splits = ['train', 'dev']
dataset = {} for split in splits: dataset[split] = DATASET['BoolQ']('your_path_to_dataset', split, bmt.rank(), bmt.world_size(), tokenizer, max_encoder_length=512) batch_size = 64
train_dataloader = DistributedDataLoader(dataset['train'], batch_size=batch_size, shuffle=True)
dev_dataloader = DistributedDataLoader(dataset['dev'], batch_size=batch_size, shuffle=False)
▶ 03 模型训练
现在,在设置优化器、学习率调整策略和损失函数后,就可以开始训练模型了!在示例代码(https://modelcenter.readthedocs.io/en/latest/notes/quickstart.html)中,我们训练 BERT 模型5轮,并且在每轮训练结束后验证模型的性能。
import bmtrain as bmt optimizer = bmt.optim.AdamOffloadOptimizer(model.parameters())
lr_scheduler = bmt.lr_scheduler.Noam( optimizer, start_lr = 1e-5, warmup_iter = 100, end_iter = -1)
loss_func = bmt.loss.FusedCrossEntropy(ignore_index=-100) for epoch in range(5): model.train() for data in train_dataloader: input_ids = data['input_ids'] attention_mask = data['attention_mask'] labels = data['labels'] optimizer.zero_grad() # model forward logits = model(input_ids, attention_mask) # calculate loss loss = loss_func(logits.view(-1, logits.shape[-1]), labels.view(-1)) # scale loss to avoid precision underflow of fp16 loss = optimizer.loss_scale(loss) # model backward loss.backward() # clip gradient norm _ = bmt.optim.clip_grad_norm(optimizer.param_groups, max_norm=10.0, scale = optimizer.scale, norm_type = 2) bmt.optim_step(optimizer, lr_scheduler)
▶ 04 运行代码
运行代码的方式和上节所给出的一样,你可以根据 PyTorch 版本选择其中的一个,具体命令可以参照上节:运行分布式训练代码中所给出的示例。
▶ 05 如何创建新的模型
- 在 ModelCenter 的
model_center/layer中,我们给出了包括像Linear、LayerNorm、Embedding等等常用模块的实现。且这些模块都是基于bmtrain.DistributedParameter和bmtrain.DistributedModule实现的,支持分布式训练。因此在创建新的模型时,我们可以直接调用这些模块,完成网络的搭建。 - 在 ModelCenter 的
model_center/layer中,我们同样实现了一些常用的模块的组合,被称作block,如组合了Attention和Add&Norm的SelfAttentionBlock。每一个block都有不同的选择, 且支持pre-layernorm和post-layernorm。 - 我们使用
bmtrain.CheckpointBlock和bmtrain.TransformerBlockList来包装我们的tranformer block。这些在不增加大量计算时间的情况下大量减少了 GPU 内存使用量。 - 在 ModelCenter 所提供的常用模型的基础上,通过加入相应的模块,你可以很容易地构建一个新的模型。你只需要将模型特定功能添加到通用的模型结构中,就可以轻而易举地实现一个新模型。
- 可以参考示例代码(https://modelcenter.readthedocs.io/en/latest/notes/write_model.html)中给出的实现方式。
未来展望
在未来,我们将在 BMTrain 中进一步完善训练的工具链,并达到更好的 PyTorch 兼容性;在 ModelCenter 中支持更多的预训练大模型,并完善模型对推理的支持。
我们诚邀更多的开发者加入我们的开发队伍,共同维护 OpenBMB 开源社区。也欢迎大家使用 BMTrain 实现更多类型的大模型,共同维护大模型构建与应用生态,为大模型时代贡献一份力量。

京公网安备 11010802039419号