
随着终端侧 AI 变革席卷全球,「小而强」的端侧大模型,成为行业主流玩家的必争之地。
面壁 MiniCPM,这颗超级能打的「小钢炮」,凭借独特的上千次「模型沙盒」实验技术路径,超越全球一众轻量高性能的标杆之作,成为小尺寸极限竞技场中的大模型王者:
- 以 2B 规模、1T tokens,和来自「欧洲版 OpenAI」的 Mistral-7B 一较高下(图1);
- 相较晚一个月发布、来自谷歌的新星 Gemma 模型,2B 量级整体领先,7B 量级多项超越(图2);
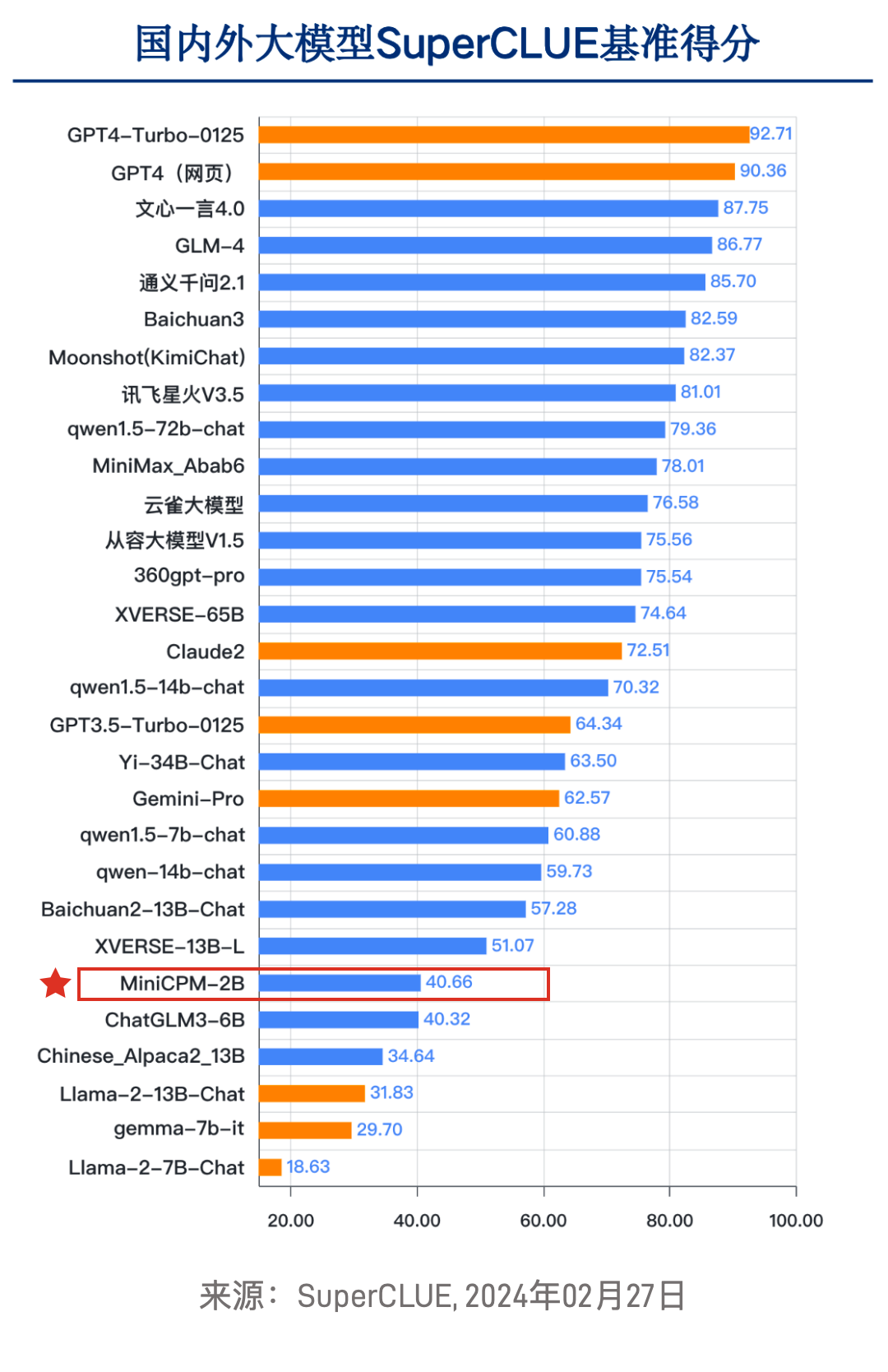
- 在刚刚放榜的 SuperCLUE 评测中,以「以小博大」亮眼表现,超越智谱的 ChatGLM3-6B, Meta 的 Llama2-13B-Chat, 谷歌的 Gemma-7b-it 等更大规模明星模型(图3)。

图1:模型性能同体量最强,越级比肩 Mistral-7B, Gemma-7B, Llama2-13B
图中模型评测均采用 UltraEval评测框架。选择常用的评测任务:C-Eval,CMMLU,BBH,MMLU,HumanEval,MBPP,GSM8K,MATH,HellaSwag,BoolQ,PIQA,WinoGrande,ARC-e,ARC-c,从不同的能力维度检验模型的能力,最终取所有任务的均值作为最终结果进行展示。
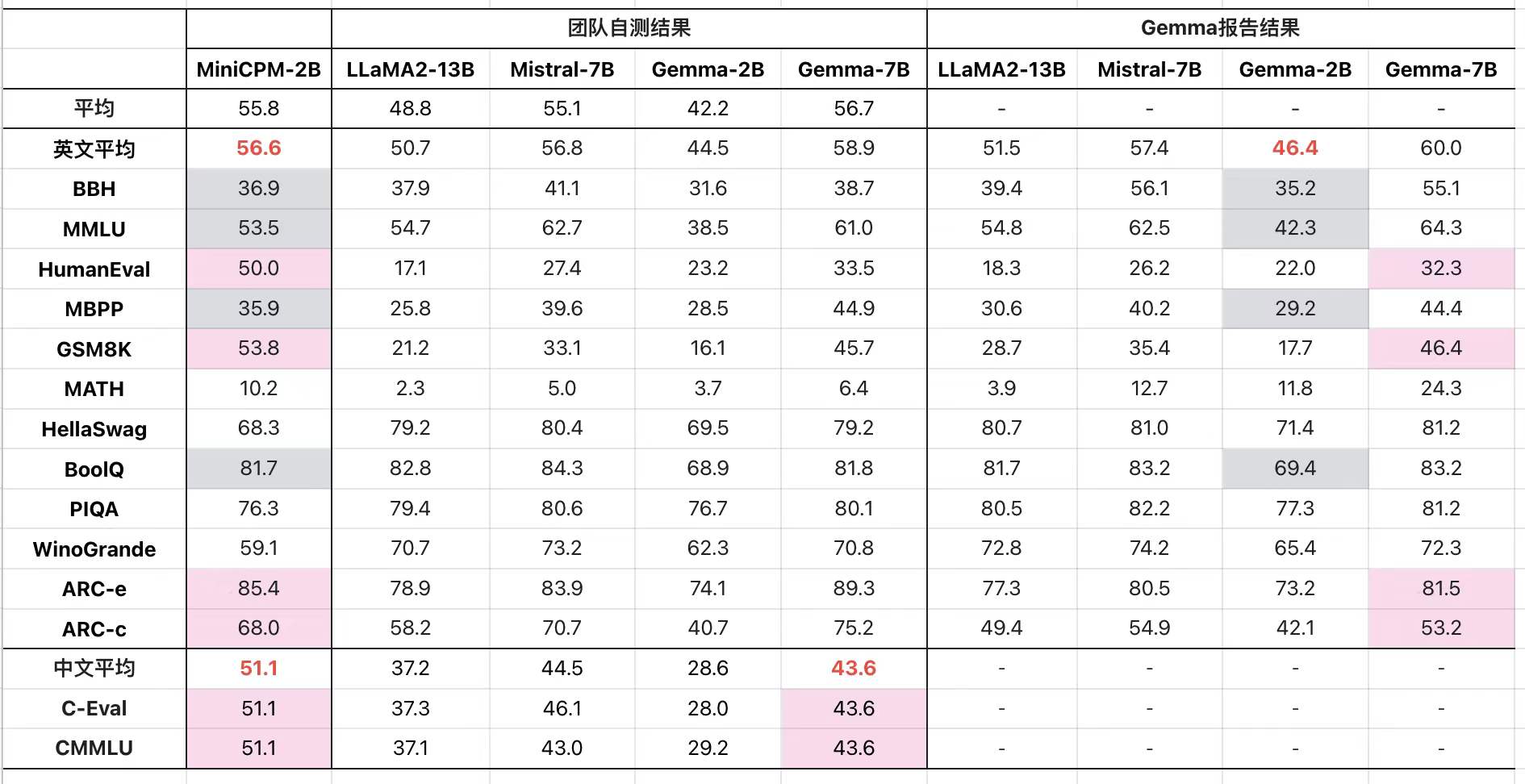
图2:面壁 MiniCPM 相较谷歌 Gemma
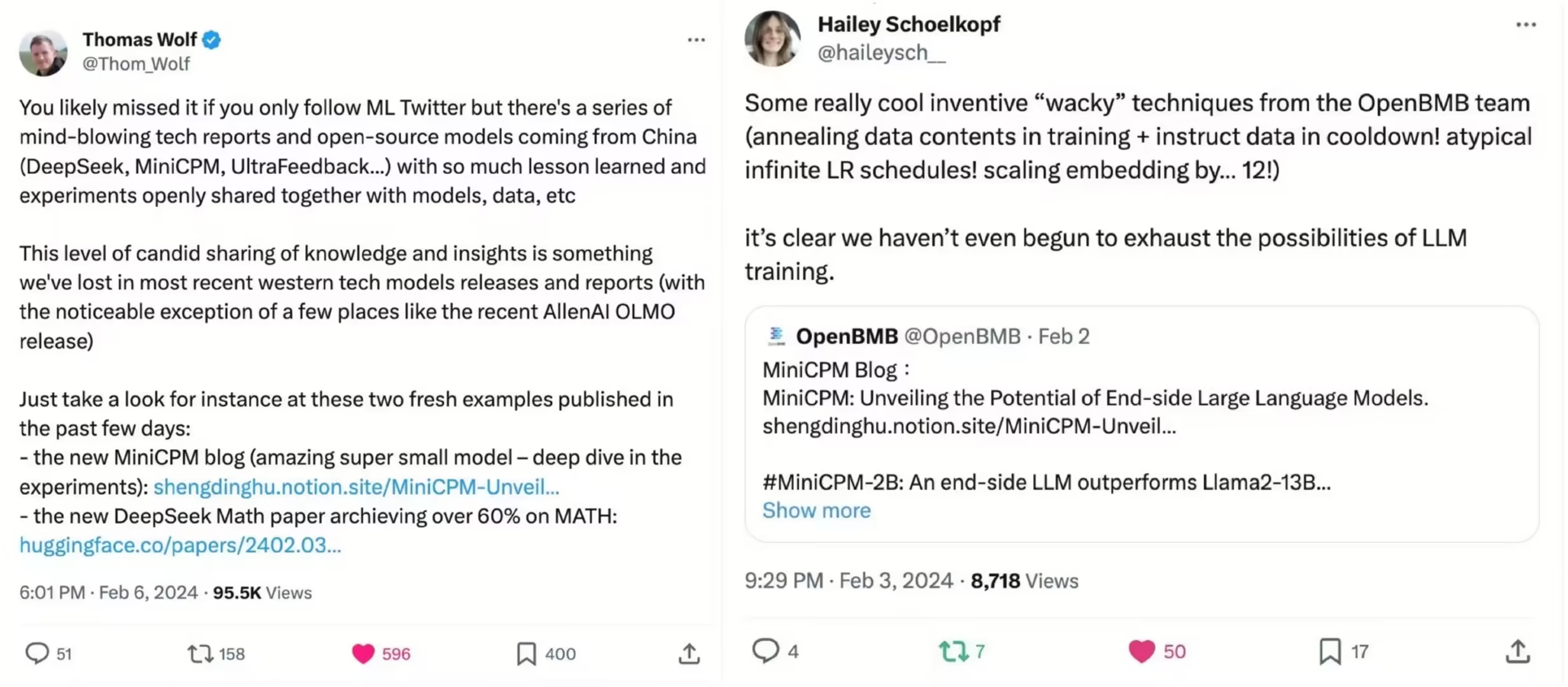
同时受到众多科技媒体赞誉(左滑查看更多):






更多讨论,欢迎加入 OpenBMB 社区

京公网安备 11010802039419号