BMCook
The toolkit for big model “slimming”. BMCook performs efficient compression for big models to improve operating efficiency.
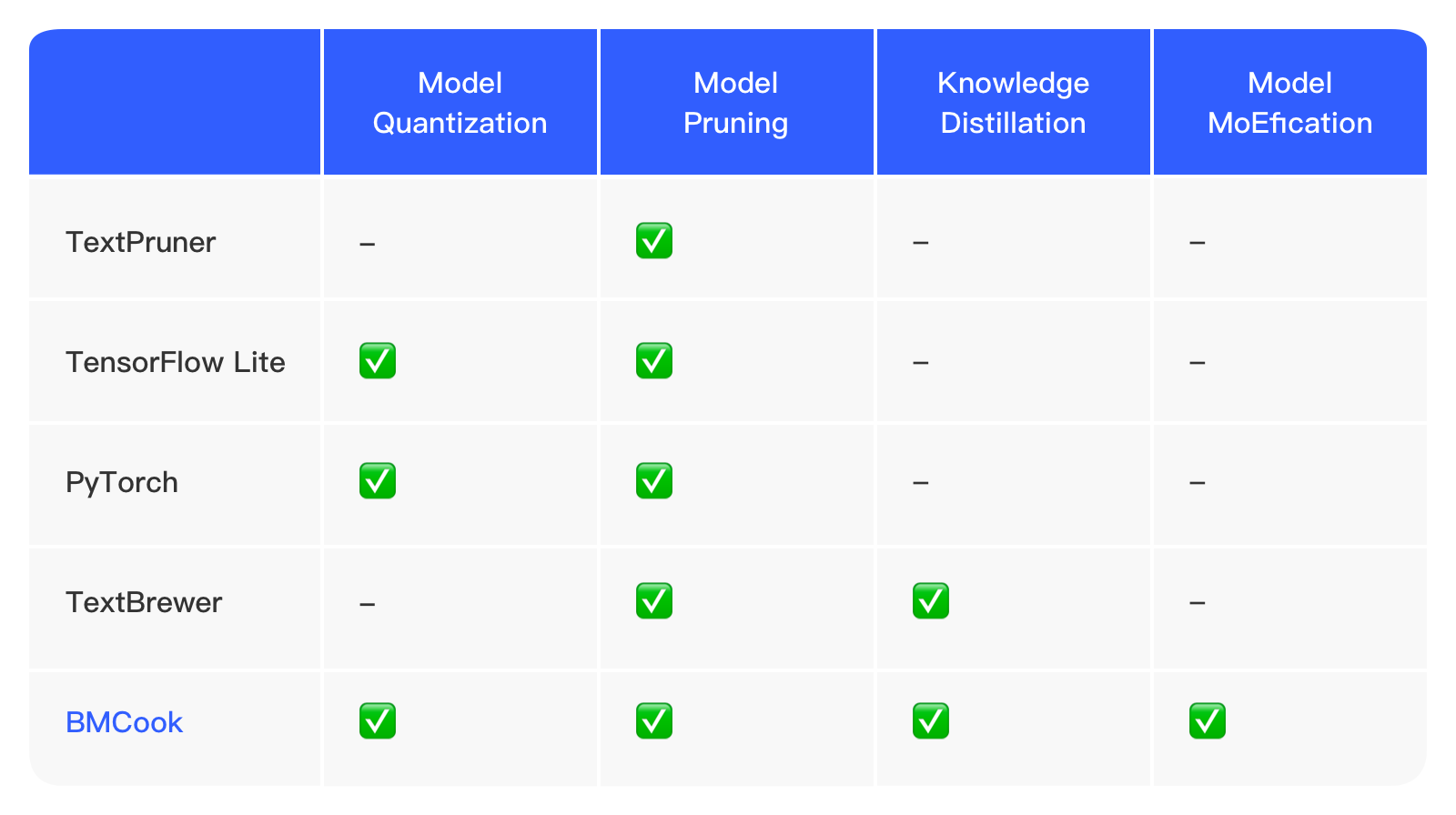
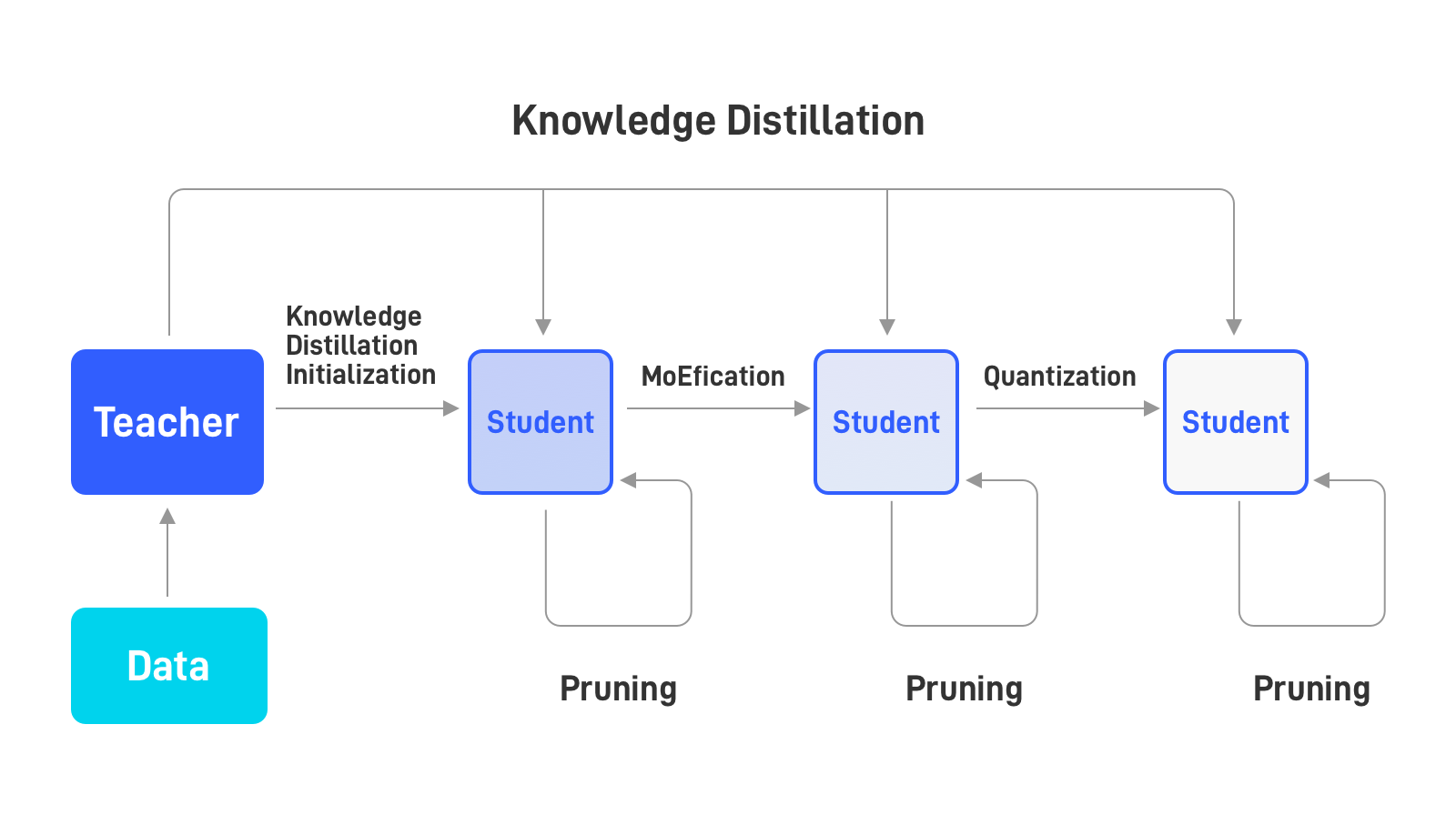
Through the combination of algorithms such as quantization, pruning, distillation, and MoEfication, 90%+ effects of the original model can be maintained, and model inference can be accelerated by 10 times.
Through the combination of algorithms such as quantization, pruning, distillation, and MoEfication, 90%+ effects of the original model can be maintained, and model inference can be accelerated by 10 times.
 GitHub
GitHubDoc
Share