CPM1
CPM1是一个拥有26亿参数的生成式中文预训练语言模型。
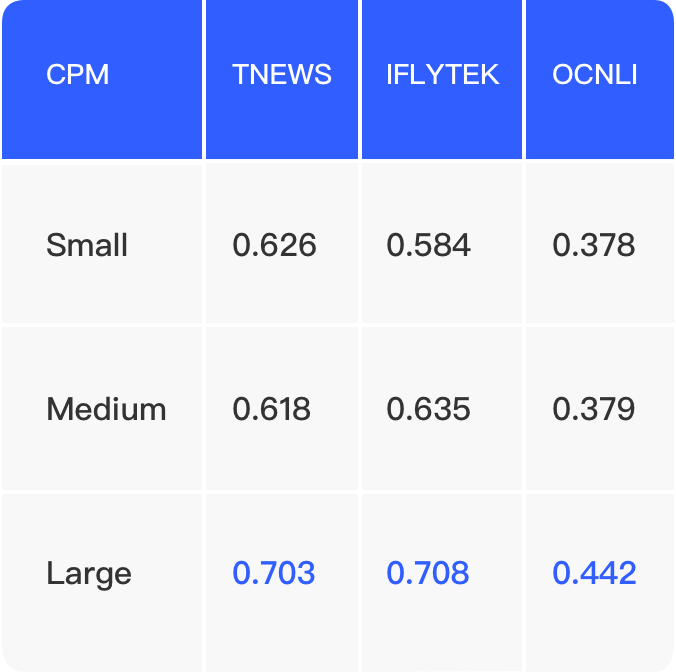
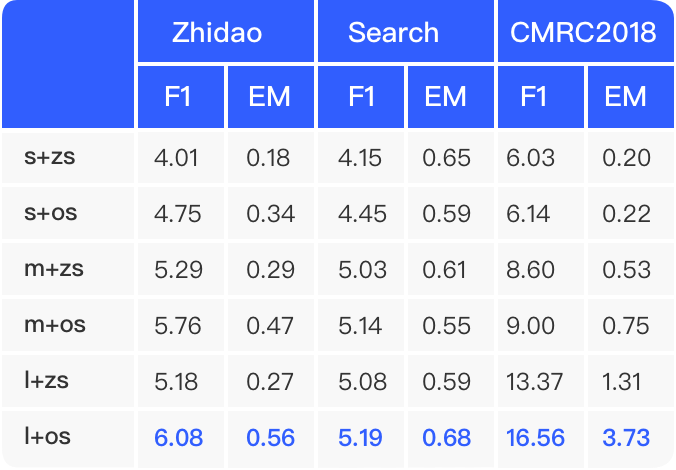
CPM1的模型架构与GPT类似,它能够被应用于广泛的自然语言处理任务,如对话、文章生成、完形填空和语言理解。
CPM1的模型架构与GPT类似,它能够被应用于广泛的自然语言处理任务,如对话、文章生成、完形填空和语言理解。
 GitHub
GitHub 使用协议



 GitHub
GitHub 






 按键盘Tab键开始生成
按键盘Tab键开始生成 
京公网安备 11010802039419号
